

Stop Paying the “Microservice Premium”
A Solution to the Microservice Deployment/Distribution Trade-Off


When evaluating microservices as a candidate architecture, the most important factor to consider is that the end result is a distributed application. Microservices are the components of distributed applications — and distribution is what enables their chief virtue, deployment independence. Unfortunately, relative to the traditional alternative, pejoratively called “monoliths”, distributed apps are much harder to build and manage. So much so, that many microservice implementations fail.
This trade-off — putting up with increased scope, cost and risk that distributed systems impose, in order to reap the benefits of a microservice-style deployment — is called paying the microservice premium. Sometimes the premium is well worth it, especially for more complex apps; but in many cases it does more harm than good, leading experts to advise against starting with microservices, but to instead introduce them gradually as complexity or volume increases.
That said, in cases where the implementation does succeed, organizations generally prefer microservices to monoliths because of the increased velocity and agility that deployment autonomy brings. So one could make the argument that if this premium were somehow discounted, microservices would be appropriate for a much wider audience, which begs the question:
Can we deploy components independently without having to distribute them?
Is there such an alternative? Fowler states the implicit premise behind the distribution/deployment trade-off:
“One main reason for using services as components (rather than libraries) is that services are independently deployable. If you have an application that consists of multiple libraries in a single process, a change to any single component results in having to redeploy the entire application.”
While technologies that actually do allow changes to libraries without redeploying the entire app, such as OSGi, have been around for a long time, it would appear they haven’t been considered a viable alternative to distributed systems…at least until now. Whatever the reason for this aversion (complexity, labor intensity, skills scarcity), with the advent of module federation, it is no longer warranted. In other words, we can eliminate the deployment/distribution trade-off and achieve deployment independence without having to distribute our application. Let’s see how.
Module Federation
Using module federation, it is possible to dynamically and efficiently import (and reimport) remote libraries, just as if they were installed locally, with only a few, simple configuration steps. Unlike other dynamic module solutions, any module can become a remote module. You don’t need to develop a module as a remote module — with the intention that it will be used as such. No code changes or complex deployment artifacts are needed. Furthermore, remote modules can be managed in separate repos, developed by separate teams, and deployed independently of the applications that import them.
As we will show, not only does this tech answer the tricky question of how to share code in a microservices architecture, but it can also be used to build applications as monolithic ensembles of independently deployable libraries, call them microservice libraries for lack of a better term.
 AWS and Netflix “Death Stars” — graphs of microservice communication paths
AWS and Netflix “Death Stars” — graphs of microservice communication paths
Distributed Systems & Death Stars
In a previous article, we considered a method of applying module federation and hexagonal architecture to build composable microservices, including a scenario in which two or more services are deployed independently but run together in a single process. (Note: The PoC project mentioned in the previous article has since been moved under the Module Federation organization. You can find it here.) While the idea of libraries as independently deployable application components is nothing new, its implementation and practice in enterprise systems is rare. For organizations looking to enjoy the main benefits of the microservice style, without its typical drawbacks, namely the premium price of distribution, or for those looking to reduce operational complexity — and perhaps fight back against a growing “death star” — a simple, lightweight, readily accessible framework for building truly modular, monolithic applications should be compelling.
Webpack
Given webpack controls the provisioning and execution of the application, it is uniquely positioned to provide the underpinnings of such a framework. Using webpack’s core competencies (dependency discovery, tree-shaking, code splitting — and now code streaming, and streaming compilation (for WASM) — we can support efficient hot deployment of federated modules, as well as any dependencies not present on the host; enabling development teams to deploy at will, without disrupting other components, and without having to coordinate with other teams.
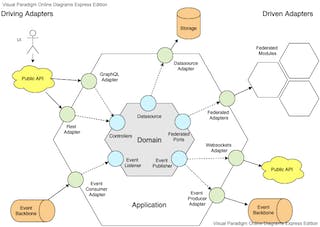 hexagonal architecture
hexagonal architecture
Hexagonal Architecture
To simplify integration, promote composability and ensure components remain decoupled, an implementation of the port-adapter paradigm from hexagonal architecture can standardize the way modules communicate, so components retain strong boundaries, while the difference between intra- and interprocess communication effectively vanishes. Components can be deployed locally and run together in the same process to take advantage of the performance and stability of in-memory communication, or remotely to scale out, run on an edge network, access protected resources behind a firewall, or integrate with 3rd party services, all with zero code changes and only minimal configuration adjustment.
N.B.: apart from the framework itself, the fact that federation virtually eliminates the need for software installation means there are no deployment artifacts for developers to worry about. Because federation works the same way in any environment (serverless, container, AWS, Azure, etc), ultimately, developers can deploy without needing to know where or on what.
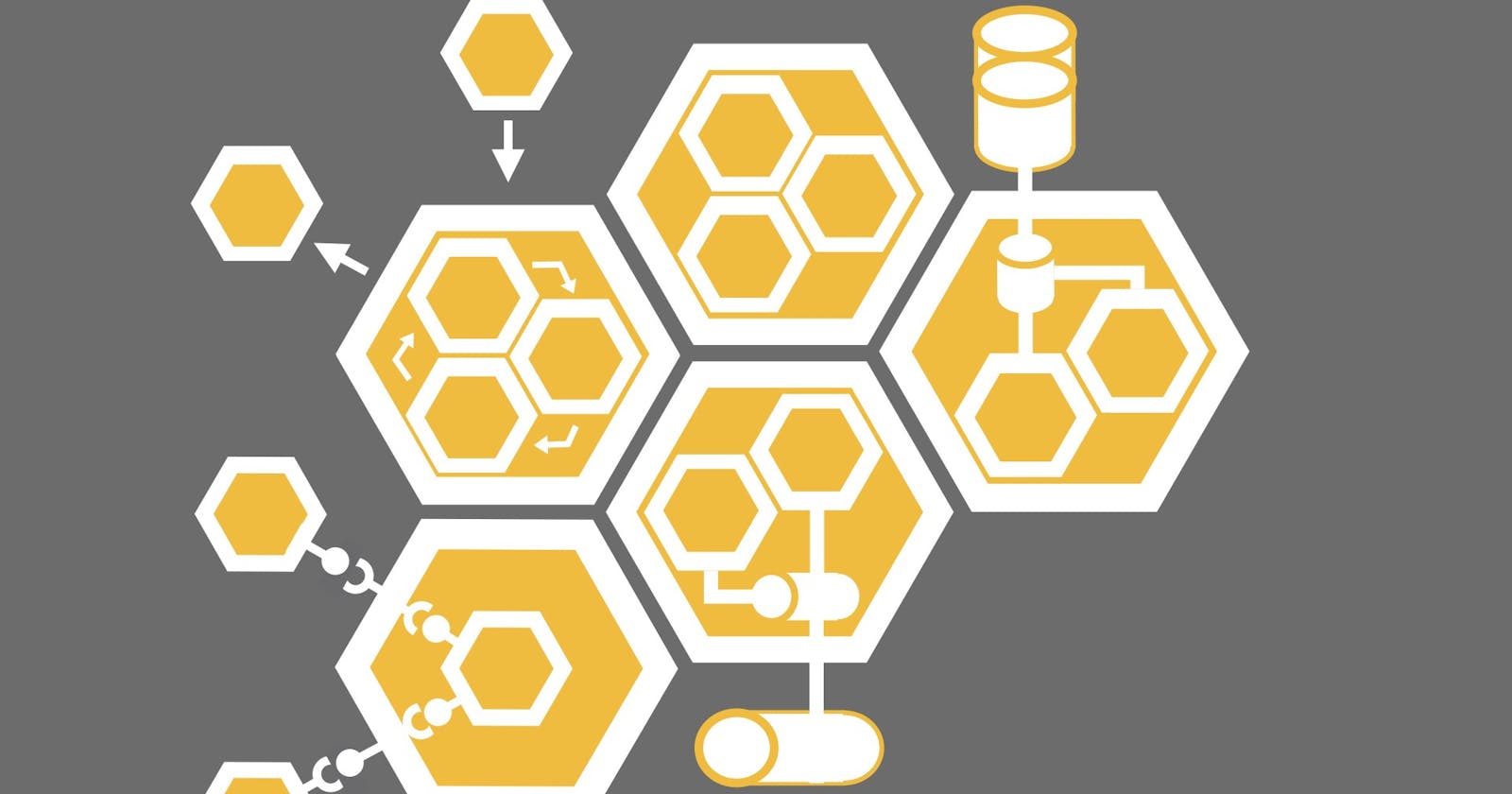
Features of a Microservice Monolith
With the goal of providing an alternative to distributed systems and the engineering and operational challenges that come with them, while preserving the benefits of deployment independence, we can organize components according to hexagonal architecture, such that the boundaries of, and relations between, federated components are clear and useful.

Components
In hexagonal architecture, we distinguish five essential elements: the domain logic or application core, which is the application’s raison d’être; ports that expose domain functions and through which all communication with the domain occurs; adapters in the application layer that implement port interfaces on one end, and consume external service interfaces, or expose interfaces for external clients to consume, on the other; and finally there are the external services for which the adapters are written.
From the viewpoint of a microservice library, a service could be a remote 3rd party application or another local microservice library. Just like a hex domain, those details are abstracted away from the component. This is no coincidence. Each service component or microservice library is designed to be a self-contained hexagonal application. This self-symmetry provides the abstraction, encapsulation and rigor needed to standardize component integration and promote strong component boundaries. While there’s no circumventing the physical network boundary in distributed deployments, logical or self-imposed boundaries in monoliths tend toward entropy if not enforced.
Just as we use Domain Driven Design to decompose a problem domain into a set of contexts and models from which we ultimately derive the set of microservices to be built, so too can we derive the set of libraries that will constitute our monolith or, depending on how we ultimately decide to deploy our components, polylith. From the perspective of DDD, which prescribes a nomenclature for our implementation, but not its technical architecture, there’s no difference.
To keep things simple, we’ll say each sub/domain model has a corresponding service or component. A model is represented in the software as an object that has a name (from the bounded context) and a factory function that creates it. The factory function sets the object’s initial state, which is immutable. State changes mean shallow clones, which preserve a history of the previous state. To define its behavior, every model has a set of zero or more ports.
Each **port** is assigned:
one or more adapters;
a service;
a direction (inbound or outbound);
a callback for processing data when it arrives;
an undo function to compensate for downstream transaction failures;
a timeout value to drive automated corrective action, i.e. retry;
a circuit breaker with error-based thresholds;
a consumer event, which is fired to invoke the port;
and a producer event, which is fired once the port function completes.
An **An adapter* is implemented as a factory function that accepts a reference to a service object and returns a function that accepts a model* and port callback as arguments. After calling the service, it transforms the payload as needed and passes it to the callback. The callback is provided by the domain and used to update the model. Because adapters are bound dynamically to ports at runtime, they can be updated live in production, e.g. to change a shipping service from UPS to Fedex; or to change a local in-memory function call to a network call.
A **service** is implemented as a namespace, object or class with one or more methods. Services provide an additional layer of abstraction for adapters and usually implement or import a client library. When an adapter is written to satisfy a common integration pattern, a service implements a particular instance of that pattern, binding to the outside end of the adapter. Services are bound to adapters at runtime and can also be updated live. E.g. when the service developer is testing the adapter, it is bound to a mock-service, but when imported by the host, it is rewired to a service module that calls the actual service endpoint.

Persistence
We want the framework to automatically persist domain models as JSON documents so we can de/serialize them from/to the network and storage subsystem. If not specified by the model, we use a default storage adapter. Providing an In-memory, Filesystem, and MongoDB adapter should make for a minimum viable product. To ensure each service controls its own data — a categorical imperative in microservices— the framework must ensure adapters can be extended and individualized per model. Additionally, de/serialization must be customizable so the model developer has fine-grained control of the data. Finally, every write operation will generate an event that can be forwarded to an external event sink.
A common datasource factory will manage adapters and provide access to each component’s individual datasource. The factory will support federated data access (think GraphQL) through relations defined between datasources. Data federation will allow clients to query aggregate data structures —i.e. structures comprised of data from multiple service components. To ensure both regular and federated data access are performant, all data will be cached. Custom datasources will leverage the cache by extending the In-memory adapter.
With local caching, not only do you have data federation, but also object federation.
const customer = order.customer(); // order has a customer relation
const creditCard = customer.decrypt().creditCardNumber;
Now consider a distributed cache, using the combination of serialization and module federation, dynamic composition and distribution is possible in a way not seen before, where new host instances are spun up or existing hosts are requested to process new services dynamically — and the data tells them where to stream the code to do it. Naturally, access to data and (what is the same thing locally) model objects requires explicit permission, otherwise components cannot execute or access one another’s code or data.

Integration
Integration is the long pole in the microservices tent, because all application components are separated by the network. In our architecture, components can be local or remote but, in most cases, run together in the same process. In some cases we need to run only a subset of components that would normally run together, requiring those components to switch to remote communication.
In light of the scenarios that can arise from composition, the framework should seek to hide integration complexity as much as possible through standardization, automation, code generation and dynamic port-adapter / adapter-service binding. The goal is to make local and remote integration as transparent as possible to the component developer and support seamless and dynamic transition from local to remote communication, and vice versa.
Distributed Cache
Using serializable objects and module federation, we can dynamically distribute application data and code amongst a network of hosts at runtime. Hosts participate in the distributed cache by subscribing to one or more cache events within a sub/domain. With the location of the federated code that controls the model encoded in its metadata or registered in a common directory (think RMI and JNDI), we can fire a cache sync event whenever the object is saved, deleted, or there is a cache miss. On receipt of the event, a host deserializes the object, imports the remote modules specified in the object metadata or common directory (if it hasn’t already), and rehydrates/unmarshals the object, at which point it can invoke the object’s methods (i.e. ports) by making in-memory function call, instead of a network call.
Of course the code is only downloaded once, (until there is a deployment request from the CI/CD toolchain). On startup, the system can check if there is a relation defined to a remote model, i.e. one that is not specified as a remote import, and import the required modules ahead of time and/or subscribe to the appropriate domain events. The distributed cache serves several purposes, but its main job is to support composition through transparent integration, allowing components to interact in a consistent and performant way, no matter how they are deployed.
Dynamically Generated APIs
Importing a remote domain model will automatically generate a set of RESTful endpoints that support CRUD operations against the model’s datasource. For an MVP release, REST is sufficient, but ultimately GraphQL support will help drive greater adoption.
Ports & Adapters
For each port configured, the framework dynamically generates a method on the domain model to invoke it. Again, each port is assigned an adapter, which either invokes the port (inbound) or is invoked by it (outbound). The framework dynamically binds adapters to ports and services to adapters at runtime.
Ports can be instrumented for exceptions and timeouts to extend the framework’s retry and compensation logic. They can also be piped together in control flows by specifying the output event of one port as the input or triggering event of another.
Again, an adapter either implements an external interface or exposes one for external clients to consume. Recall that, in our architecture, an external service or client can actually be another local service component (microservice library). On the port end, an adapter always implements the port interface; never the other way around. Ports are a function of the domain logic, which is orthogonal to the environment in which it runs or the means by which data are transmitted.
Ports can be configured to run on receipt of an event, API request, or called directly from code. As previously mentioned, ports also have an undo callback to compensate for downstream transaction failures. The framework remembers the order in which ports are invoked and runs the undo callback of each port in reverse order, starting at the point of failure. This allows transactions across multiple services to be rolled back.
Local & Remote Events
In addition to in-memory function calls, federated objects and ports, services can communicate with one another locally the same way they would remotely: by publishing and subscribing to events. Using local events, microservice libraries are virtually as decoupled as they would be running remotely.
The framework provides a common broker for local service events and injects pub/sub port functions into each model:
ModelA.listen(event, callback); // outbound port
ModelB.notify(event, data); // inbound port
Local events can also be forwarded to remote event targets. Like any external integration, additional ports must be configured for external event producers or consumers. In its first release, the framework should provide adapters for Kafka and WebSockets to support the event-driven architecture pattern.

Service Orchestration
Service orchestration is built on the framework’s port-adapter implementation. As mentioned, ports both produce and consume events, allowing them to be piped together in control flows by specifying the output event of one port as the input event of another. Because events are shared internally and can be forwarded externally, this implementation works equally well whether services are local or remote.
Callbacks specified for ports can process data received on a port before its output event is fired and the next port runs. If not specified, the framework nevertheless saves the port output to the model. Of course, you can implement your own event handlers or adapter logic to customize the flow.
Zero-Install & Hot Deployment
Module federation eliminates the need to install software during an upgrade. Software upgrades are readily automated and incredibly efficient. Under the proposed framework, federation is integrated into the CI/CD pipeline for this purpose. In addition, the framework eliminates downtime due to software updates through its hot deployment capability. Deployments are done live with zero downtime and zero disruption of client connections. The framework makes use of host-remotes or self-federation for closures that ensure clean disposal and reload of module cache. This is the key to non-disruptive, independent deployment.
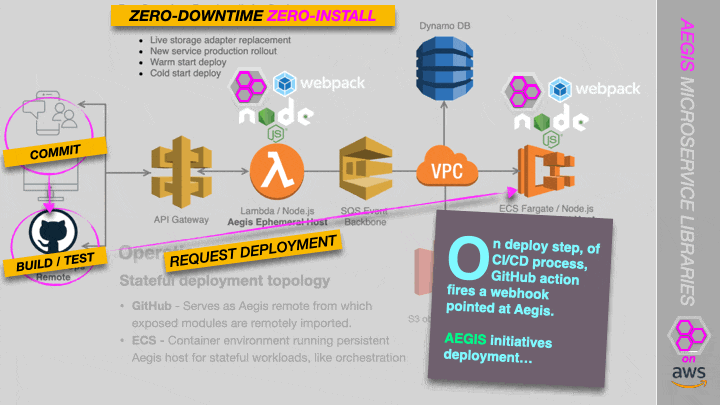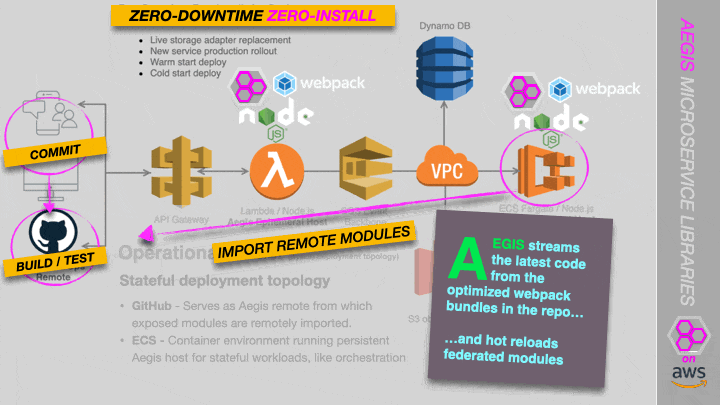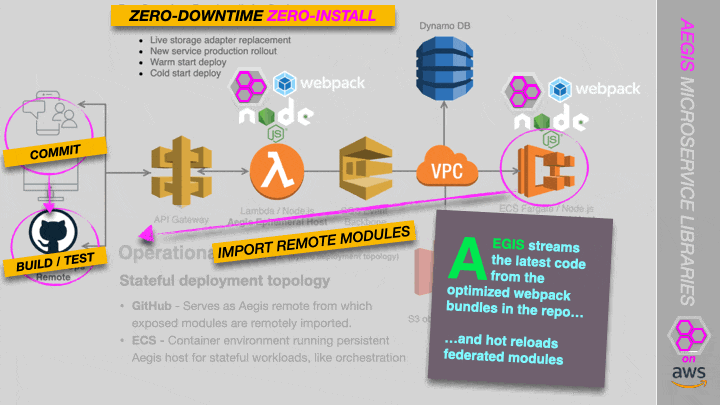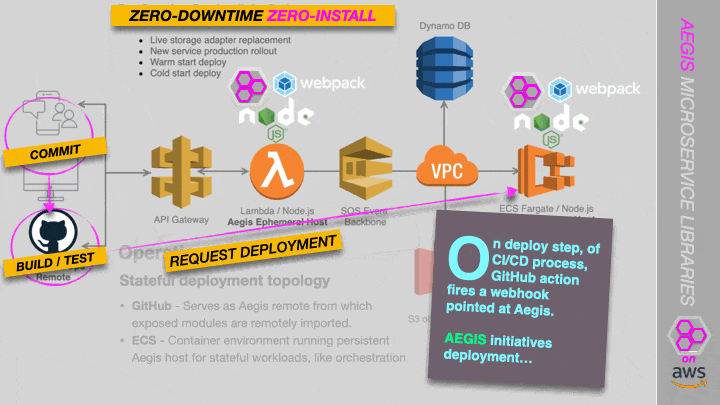
Reference Architecture
A Proof of Concept is currently underway of a serverless (Lambda) and container-based (ECS) deployment topology, in which we stream code directly from GitHub. See the screenshot below. More on this soon.
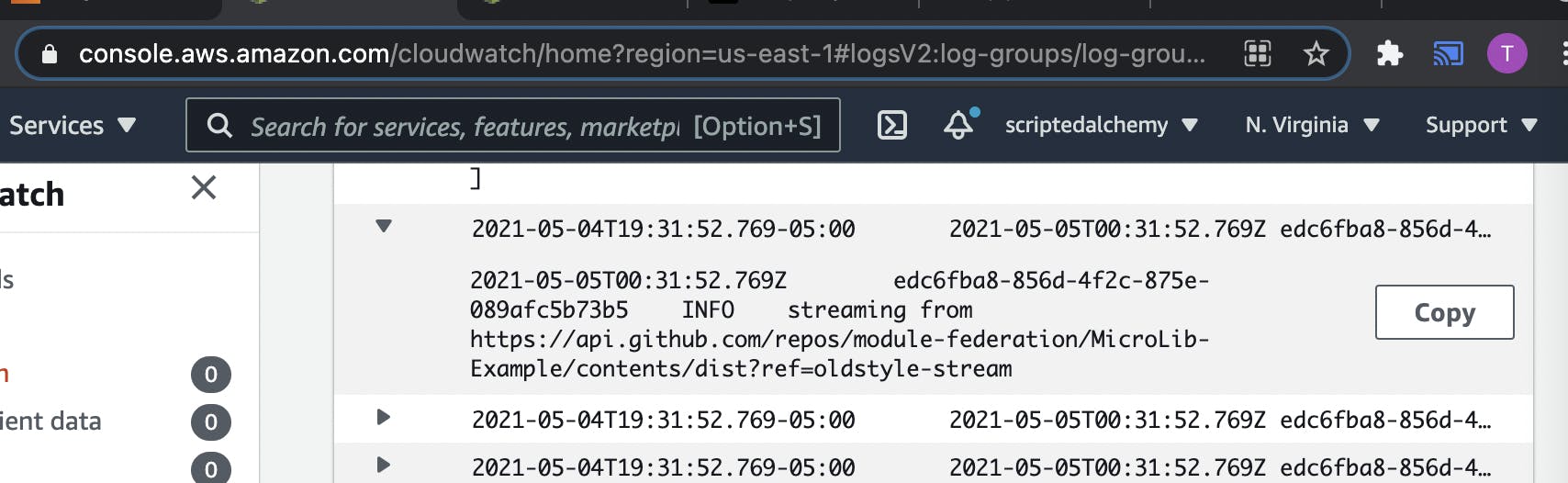 AWS streaming code from GitHub on cold-start
AWS streaming code from GitHub on cold-start
Polyrepo-friendly
With module-federation there’s no need for a monorepo to share code between services. For some organizations, moving to a monorepo might be considered impractical if there was a way to avoid it. Now there is.
Conclusion & Outlook
In this article, we have offered a solution to the microservice deployment/distribution trade-off. We have described in detail an architecture and software framework that can eliminate the most problematic aspects of the microservice architectural style while preserving the most advantageous; thereby providing an opportunity for organizations that might otherwise shy away from microservices to take advantage of the benefits without incurring the costs, both of which are known to be significant.
For those used to enjoying all the benefits of microservices, one downside or limitation, apart from being opinionated about component boundaries and immutability, is that the solution is not polyglot. As a CTO, I’d be too distracted by the upside to care. As a developer, its still a negligible price to pay when you consider your cost avoidance with respect to engineering difficulty and operational complexity. You could always develop outside the framework if needed. With the right team, you can do just about anything. On that note, WebAssembly and its support for dynamic modules is a potential avenue for research.
For all the other reasons above, this new alternative in cloud-native application design deserves serious consideration. Work continues on the open source framework under the aegis of the Module-Federation org. Look for more on this topic in the coming weeks and months.
UPDATE: within a week of writing the above, we were federating Rust using WebAssembly. (Thanks Alex!) Getting harder to find a downside…
Additional Content: Federated Microservices Manageable Autonomytrmidboe.medium.com
See the framework: module-federation/MicroLib MicroLib is a lightweight API framework built on Node.js that uses module federation to host and integrate multiple…github.com